Esta semana (11-17 marzo de 2019), dentro de la semana del #OpenWeek mundial, se han realizado distintos eventos de Datos Abiertos en Panamá. Hoy fue el evento quizás principal de la semana, llamado “Panamá Abierto”, organizado por la ANTAI dentro del CAIC (Centro de Acceso a la Información Panamá-Corea), donde también funciona el ITI (Instituto de Tecnología e Información), en Ciudad del Saber.
La verdad es que quedé impresionado por los avances que se están realizando en Panamá en cuanto a la apertura de datos en el sector gubernamental, todo impulsado por parte de la ANTAI y con apoyo también de organismos como la AIG, OEA y The Trust for the Americas (parte de la OEA).
Luego del evento principal, el grupo se separó en tres mesas de trabajo, donde una de las tres mesas estaba relacionada con la Guía de Datos Abiertos y el Portal de Datos Abiertos. La guía, como base, está muy bien elaborada, igual que el Portal.
Al momento de iniciar el proceso, se discutieron algunas preguntas. Uno de los participantes en la mesa habló sobre un problema de granularidad de los datos que se han ido publicando, a lo que complementé con mi experiencia personal y mencioné que debemos buscar que los datos se aperturen de forma completa, que en vez.
La respuesta de uno de los otros intervinientes fue de calificar esto como una “utopía” y que en Datos Abiertos debíamos desplegar la información procesada, a lo que volví a verificar si estaba en un evento de Datos Abiertos o de Información Abierta.
#.Datos, Información y Conocimiento
A partir de aquí surgió un debate que creo que muchos desconocen y es importante aclarar.
Todo el proceso de generación de Datos, como cualquier otro proceso de explotación y exploración de datos, tiene como vista la generación de conocimiento.
La generación y la gestión del conocimiento son nuevos términos dentro de las ramas de la tecnología, es por eso que hemos pasado de hablar de “Tecnologías de la Información” a “Tecnologías del Conocimiento”.
De hecho, yo estudié “Tecnologías del Conocimiento”, para aclarar que no se trata solo de la explotación del Dato si no de la interpretación del mismo en etapas mucho más completas.
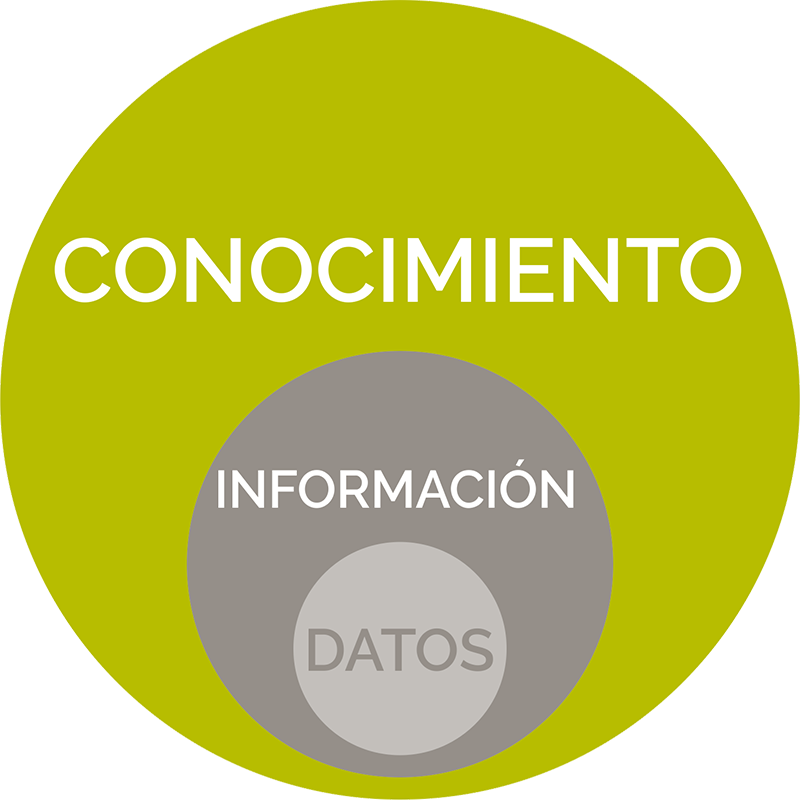
Es por ello que tenemos, en realidad, tres términos importantes:
- Dato: Es la unidad más pequeña, cruda, sin procesar. Son la mínima unidad semántica y primaria. Por si solos, deben ser irrelevantes.
- Información: Son los datos con significado adquirido a partir de la incorporación de relevancia, propósito y contexto.
- Conocimiento: Es utilizar esta información, mezclarlo con experiencias y know-how para la interpretación y toma de decisión.
Es decir:
- si nosotros tenemos listados de medicamentos y las cantidades de los mismos en todas las farmacias del seguro social, desplegados secuencialmente (datos),
- pero luego a través de ese dato generamos reportes o estadísticas (información),
- que nos complementen para decidir en qué farmacias del seguro social tenemos más incidencias en falta de medicamento (conocimiento).
#.Los reportes están bien, pero requerimos la fuente de los mismos
Más que requerir estadísticas, reportes, información desglosada y categorizada de distintas formas, es más útil para todos nosotros que se publique la fuente de los mismos.
¿Se imaginan cuántos posibles reportes se podría generar a partir de una misma fuente de datos? Es por ello que, ¿no sería más adecuado ofrecer el dato crudo, para que las personas puedan decidir la forma en que contextualicen dicho dato para sus necesidades propias?.
Dicho de otro modo, y a través de una analogía, tal como lo dije ya en Twitter y en otras redes sociales:
Analógicamente. En vez de que se entregue todo cocinado y en plato, listo para comer (información), preferiblemente entregar los ingredientes para que podamos decidir que queremos comer en base a todo lo que podríamos cocinar (dato). Yo quiero ser chef del dato.
Creo que esto es de suma importancia y es importante, para cualquier otro proceso futuro, comprender y diferenciar el porqué es tan útil y necesario la apertura de datos y no de información.